Or: How I Learned to Stop Fighting Cold-Starts and Embrace Bounding Box Density
TL;DR: Training deep neural networks for object detection demands an immense bucket of annotated images, which gets incredibly expensive. Semi-supervised methods help, but they constantly fall short of full supervision upper bounds. We built HUALE-a framework that couples a robust two-stage retrieval and ranking pipeline with a localized “Emphasis loss”. It consistently beats baseline detectors across PASCAL VOC and MS COCO benchmarks while saving huge on labeling workloads.
This all started because data curation loops are severely bottlenecked by manual human annotation. Traditional active learning pipelines choose what images to label next based solely on category classification entropy or standalone bounding box fluctuations. But flatly stacking metrics ignores the deep, messy rift between a detector’s classification head and its bounding box regression branch.
Our solution? We proposed HUALE (Hierarchical Uncertainty Aggregation and Emphasis Loss). Instead of confusing the model with conflicting multidimensional signals all at once, it screens images down an organized, sequential filtration cascade.
The Evolution of a Pooling Hack
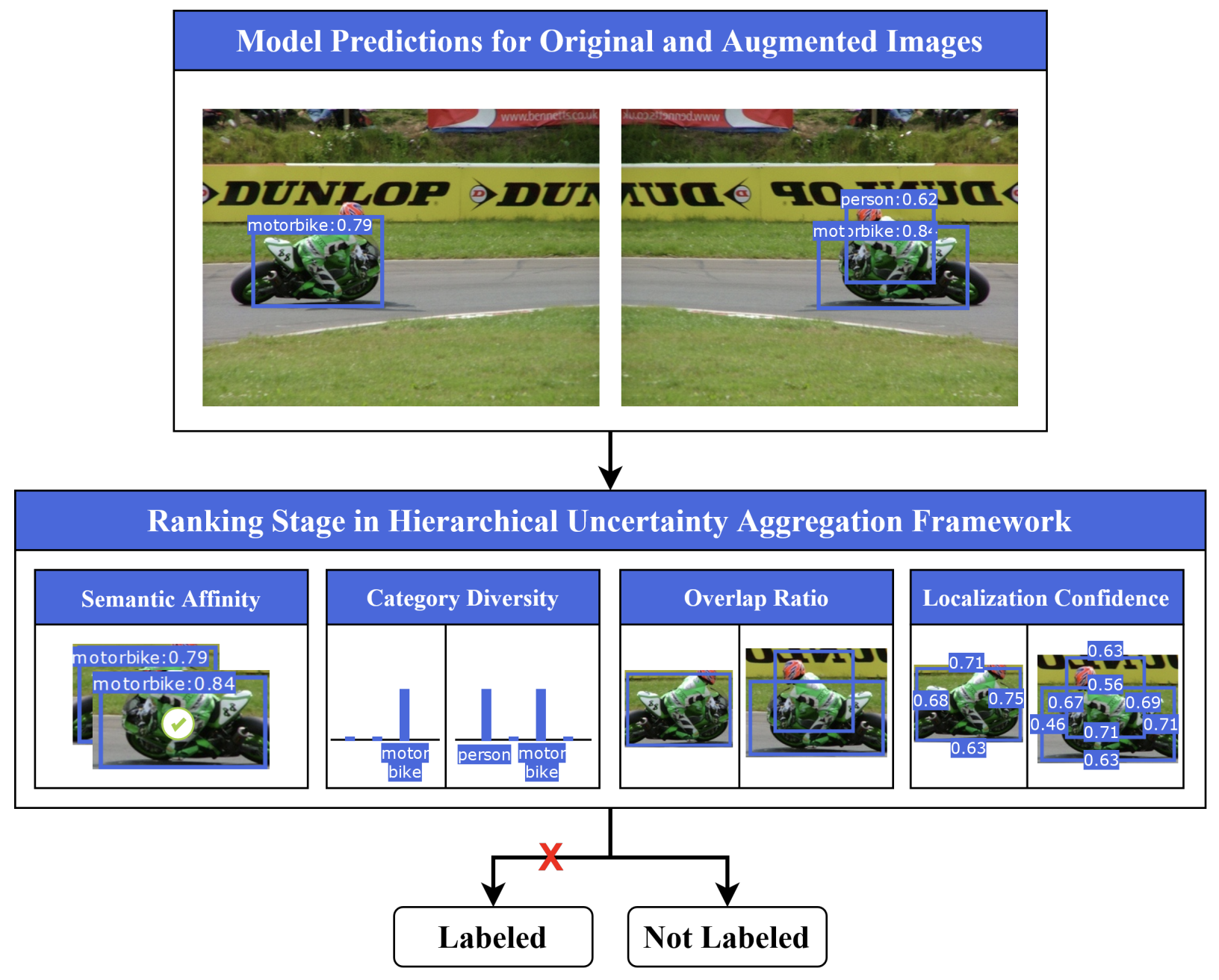
When evaluating unlabeled pools, consistency-based active learning methods look at how much a prediction changes when you flip or distort the input image. If a model spots a vehicle smoothly on an original image but completely blank-screens when you pass it a horizontally flipped version, that discrepancy screams unpredictable training value.
However, mapping these spatial overlaps can quickly turn into a messy aggregation nightmare:
-
Standard summation or averaging of raw bounding box shifts can crash when one image branch fails to trigger any proposal hooks at all.
-
Tuning multiple hyper-parameter weights across different objective models often brings model volatility to a screeching halt, landing you squarely in the notorious active learning “cold-start” problem.
We needed an explicit framework that separates rough image screening from granular object ambiguity while supercharging the initial detector training loop.
Plot Twist: Hierarchical Cascade Filtering
To bypass standard score-clumping downfalls, our Hierarchical Uncertainty Aggregation (HUA) engine splits sample selection into two distinct validation steps: Retrieval and Ranking.
1. The Retrieval Gate
First, we run the massive pool of unlabeled images through a high-level entropy sweep. Using basic class probability profiles, it maps overall data unpredictability and drops easy, low-entropy samples completely from the queue. Only the top confusing candidates make it through to the next room.
2. The Multi-Objective Ranking Stage
Once the pool is filtered down to a strategic size, we throw the surviving samples into a dense multi-dimensional ranking algorithm governed by four distinct metrics:
-
Semantic Affinity (SA): Quantifies probability dissimilarity between matched boxes on flipped views using a bounded Bhattacharyya distance mechanism paired with IoU score shaping.
-
Category Diversity (CD): Checks for class-label flips between original and augmented variations, weighted heavily by high-confidence class triggers.
-
Overlap Ratio (OR): Evaluates the spatial density of overlapping predicted bounding boxes to flag object clutter and occluded clusters.
-
Localization Confidence (LC): Pulls explicit localization regression variances directly from an auxiliary uncertainty-aware head.
By normalizing these metrics into a unified scalar using Euclidean optimization (), the system precisely targets instances where the model is fundamentally confused.
The Problem: The Localization Bias
Even with a flawless selection strategy, early-stage models suffer immensely from noisy localization predictions. Standard loss architectures end up heavily biased toward simple or extremely broken bounding box targets:
-
They treat multi-coordinate regressions as four completely isolated, independent numbers.
-
Standard IoU calculations flatline when boxes don’t overlap, failing to cleanly balance low-IoU versus high-IoU adjustments during backpropagation.
The Solution: Dynamic Bounding Box Emphasis
To remedy this, we augmented the regression framework by implementing Emphasis Loss paired with a specialized Synchronic IoU-Localization loss.
First, we isolate the total localization branches and scale the losses using dynamic emphasize factors ( and ):
Next, we introduce our Emphasis IoU (EIoU) loss, taking a cue from traditional focal parameters () to intelligently tweak weight allocation:
# Conceptual layout for Synchronic Bounding Box loss stabilization
def compute_synchronic_loss(pred_boxes, target_boxes, aware_variance):
# Directly optimize standard smooth L1 coordinates
l_loc = smooth_l1_loss(pred_boxes, target_boxes)
# Scale up hard vs fine examples dynamically using EIoU
l_eiou = (1 + compute_giou(pred_boxes, target_boxes))**0.8 * (1 - compute_giou(pred_boxes, target_boxes))
# Sync coordinates with an uncertainty-aware regression loop
l_aware = (1 / (2 * aware_variance**2)) * l_loc + 0.5 * log(aware_variance**2)
# Dynamic parameter matching scales the loss end-to-end automatically
return lambda_param * l_eiou + (1 - lambda_param) * (l_rpn + l_aware)
This structural modification keeps the objective monotonic, scales cleanly across minibatches, and dramatically mitigates localized boundary mistakes without breaking structural backbone logic.
Testing Our Implementation
We pitted HUALE directly against cutting-edge active learning strategies (including CALD, VAAL, and LL4AL) on Faster R-CNN task configurations.
Benchmark Model Evaluation
| Method | VOC 2007 (mAP %) | VOC 2012 (mAP %) | MS COCO (AP 0.5:0.95 %) |
|---|---|---|---|
| Random (Baseline) | 43.1 (at 10%) | 41.5 (at 10%) | 17.2 (at 5k images) |
| CALD | 74.9 (at Last Cycle) | 69.4 (at Last Cycle) | 21.72 (at Last Cycle) |
| HUALE (Ours) | 77.0 (at Last Cycle) | 71.0 (at Last Cycle) | 22.20 (at Last Cycle) |
Our framework shows its absolute highest performance gains during early-cycle runs-demonstrating a massive +8.5% mAP jump on VOC 2007 right out of the gate thanks to the stabilizing benefits of our dynamic Emphasis loss components.
The Bottom Line
Scaling modern object detectors efficiently down active learning data pipelines requires:
-
Shifting away from standard classification-only acquisition logic.
-
Utilizing split hierarchical workflows (Retrieval + Ranking) to cut through background noise.
-
Balancing boundary regressions with explicit spatial overlaps and variance tracking.
-
Injecting synchronically scaled regression rules to completely conquer initialization instability.
Active learning on two-stage architectures is notoriously tricky, but flattening your uncertainty cascade will consistently save your validation numbers.
@INPROCEEDINGS{10386534,
author={Nguyen, Tai and Nguyen, Khoa and Nguyen, Thanh and Nguyen, Tri and Nguyen, Anh and Kim, Karrman},
booktitle={2023 IEEE International Conference on Big Data (BigData)},
title={Hierarchical Uncertainty Aggregation and Emphasis Loss for Active Learning in Object Detection},
year={2023},
volume={},
number={},
pages={5311-5320},
keywords={Location awareness;Training;Uncertainty;Semantics;Estimation;Object detection;Detectors;Active Learning;Object Detection;Uncertainty Estimation;Localization Loss;Deep Learning},
doi={10.1109/BigData59044.2023.10386534}}